
Nomad on OpenShift: The case for the control plane
If Red Hat trusts OpenShift to run the control plane for their largest infrastructure orchestrator, the same pattern should apply to your smallest.

The challenge of running workload orchestration at the edge has historically presented organizations with an uncomfortable choice: extend Kubernetes to devices it was never designed for, or maintain entirely separate infrastructure for edge fleet management. Neither option is particularly appealing - the former pushes a heavyweight control plane onto resource-constrained hardware, while the latter fragments operational practices and multiplies the expertise required to keep applications and services running.
However, in August 2024, Red Hat announced the general availability of a Red Hat OpenStack release they referred to as the ‘next generation’ of the platform, and it offers a different perspective on this problem. With Red Hat OpenStack Services on OpenShift (RHOSO), Red Hat has deprecated the previous deployment model - the Undercloud and Director - in favour of running the OpenStack control plane as Operator-managed containers on OpenShift, with the data plane remaining on external Red Hat Enterprise Linux (RHEL) compute nodes. The premise is simple enough; Kubernetes excels at managing multi-service applications with high availability requirements, while the data plane belongs on infrastructure purpose-built for its workload characteristics.
It’s not unreasonable, then, to apply this same logic to the opposite end of the scale. Whereas RHOSO solves large-scale orchestration - enterprise bare metal, hundreds of cores per node, co-located datacenter infrastructure - HashiCorp Nomad addresses the small-scale challenge: lightweight edge devices, heterogeneous platforms, intermittent connectivity, and workloads that do not fit the container model.
In this post, we will explore the architecture of running HashiCorp Nomad servers on Red Hat OpenShift to manage distributed edge fleets. This is not about running two competing orchestrators for the same problem space - it’s about using the strengths of the platforms and their respective ecosystems. Red Hat OpenShift provides enterprise-grade lifecycle management for the Nomad control plane while Nomad extends scheduling capability to places OpenShift can’t, or shouldn’t, go.
Architecture overview
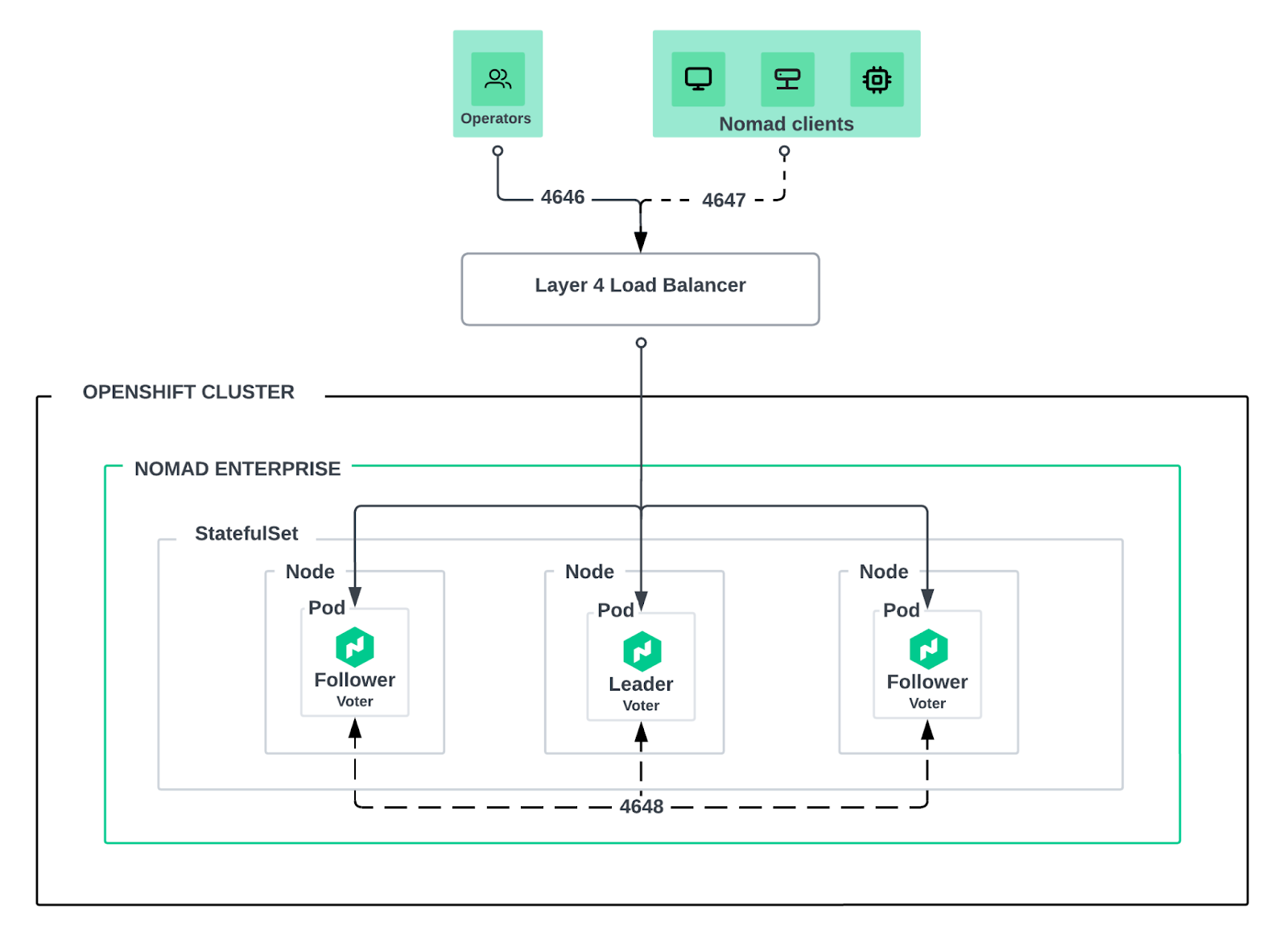
This architecture places the Nomad server nodes onto the OpenShift cluster with Nomad client nodes running on their respective infrastructure platforms - edge devices, single board computers, GPU-enabled datacenter servers, and similar infrastructure.
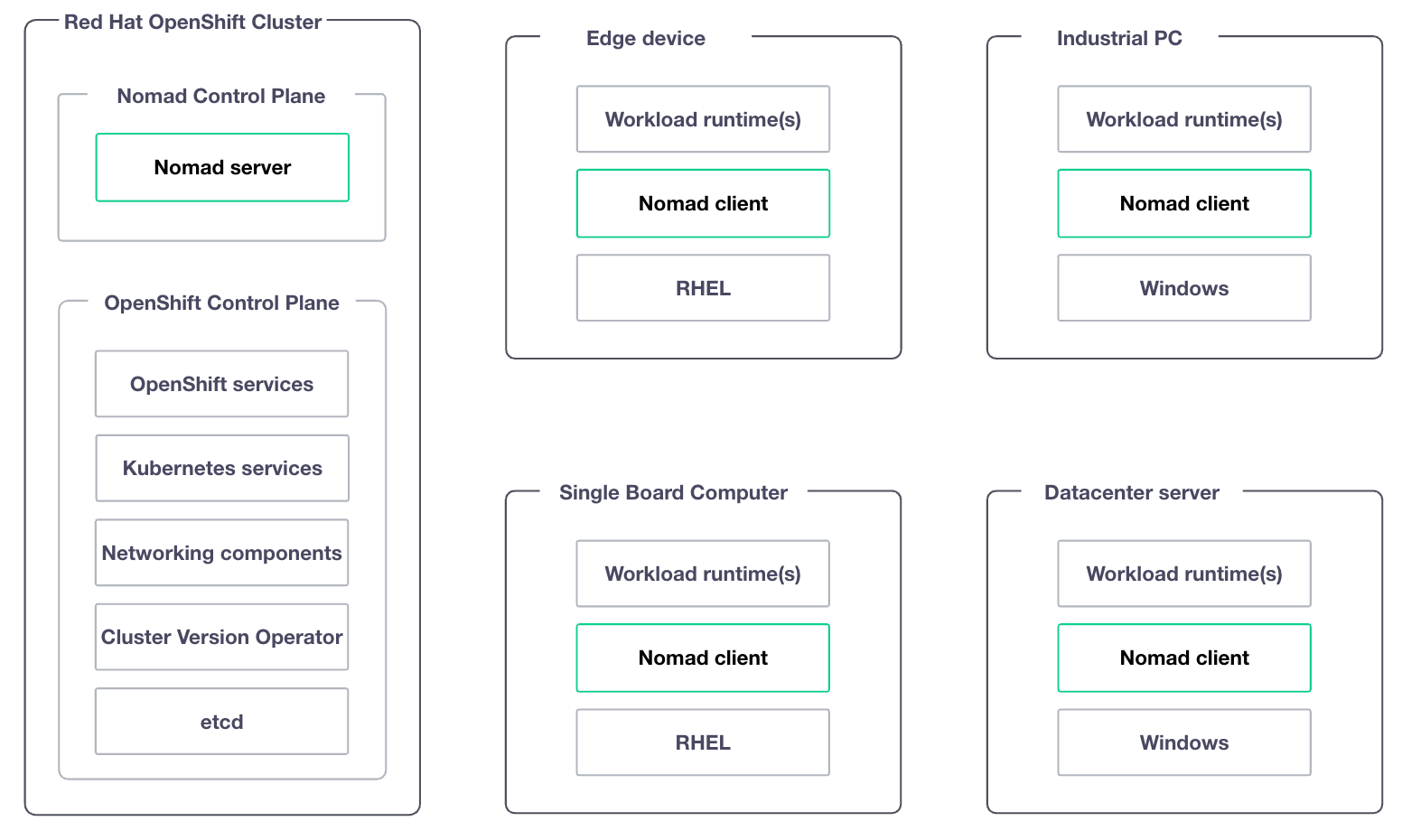
Within OpenShift, the Nomad servers are deployed as a StatefulSet, exposed to external clients via a Kubernetes load balancer service. That service could be MetalLB in an on-premise deployment, or a cloud-native load balancer in cloud or managed OpenShift environments, such as Red Hat OpenShift on AWS or Azure Red Hat OpenShift.
Nomad clients can then run on whatever infrastructure makes sense for the workloads. Edge gateways running RHEL, ARM-based single board computers, Windows industrial PCs, or traditional datacenter servers can all register with the same server cluster to receive allocations. The Nomad binary is small enough to run on resource-constrained devices and tolerant enough to handle intermittent connectivity without disrupting running workloads.
From a networking perspective, the use of the load balancer service pattern ensures that the non-HTTPS/SNI traffic on which Nomad relies to facilitate communications between server and client can traverse the OpenShift cluster boundary cleanly. Nomad clients establish outbound RPC connections to the Nomad servers and maintain them for heartbeats, allocations, and log streaming. This means your edge devices don’t need to be directly addressable from the control plane - a fact that can simplify firewall rules and NAT traversal in distributed deployments.
This architectural pattern also changes how you think about cluster topology. Nomad scales comfortably to thousands of nodes without extensive tuning, and the typical recommendation is to leverage node pools and namespaces for tenant isolation within a single Nomad cluster. However, when standing up a Nomad control plane becomes a Kubernetes-native deployment rather than an infrastructure project, you have further flexibility. If compliance, operational, or organisational concerns benefit from isolation at the platform level, you can deploy isolated Nomad server clusters per team, environment, or region - each in its own Kubernetes namespace with role-based access controls (RBAC) controlling who can manage it. If one control plane experiences issues, the blast radius is contained; other clusters continue operating independently. Nomad’s federation capabilities remain available if you need cross-cluster visibility, but isolation becomes the default rather than the exception.
Finally, it’s worth noting that the proposed deployment model of the Nomad control plane on OpenShift also lowers the barrier to entry. Traditional Nomad deployments - VMs, load balancers, storage providers, monitoring infrastructure - carry enough overhead that you might reasonably wait until your edge fleet justifies the investment. However, when the control plane is a standard Kubernetes deployment onto an existing OpenShift cluster, you can adopt centralized orchestration from day one. This shift in perspective allows even small fleets to take advantage of Nomad’s enterprise workload orchestration capabilities without the infrastructure overhead of a standard Nomad deployment.
What does Nomad bring to the edge?
Nomad really shines when orchestrating workloads on resource-constrained and heterogeneous infrastructure by focusing on characteristics that Kubernetes does not prioritize - and in some cases, explicitly trades away. Features like the container runtime abstraction, sidecar-based service mesh integration, and etcd’s strong consistency model all make sense for well-connected datacenter deployments, but add overhead that’s harder to justify given the resource constraints and network realities of typical edge fleets.
Footprint
The footprint difference is significant. The Nomad binary is just over 150MB and has a minimal runtime overhead, leaving the majority of device resources available for workload runtimes. On a single board computer or an industrial gateway, for example, that headroom really matters.
Flexibility
Nomad schedules a lot more than just containers; the exec driver runs binaries directly on the host, the Java driver runs JARs without the containerization overhead, and there is a whole ecosystem of task drivers available irrespective of the architecture or operating system of your host. If your edge workload doesn’t fit in a container, or containerizing it creates more problems than it solves, Nomad doesn’t force the issue. This is particularly relevant for legacy applications or vendor-supplied software that was never designed with containers in mind, but still needs to be deployed and managed consistently across a fleet.
This flexibility carries through to platform heterogeneity. ARM64 single-board computers, x86 industrial PCs, and Windows servers can all register with the same Nomad cluster, with job authors targeting workloads using constraints and node pools. You’re not maintaining separate clusters for each platform or architecture - the control plane handles the diversity, and the job specification captures the constraints.
Connectivity
It’s important to highlight the connectivity model. Nomad’s disconnect block lets you configure how the control plane handles network partitions. Allocations continue running on disconnected clients and can reconnect gracefully when connectivity returns, rather than being immediately marked lost and replaced. For edge sites with intermittent connectivity, this makes graceful handling of network partitions a configuration choice rather than an architectural limitation. To explore this in a number of real-world use cases, it’s worth reviewing the blog “Managing Applications at the Edge with HashiCorp Nomad”.
Integration
If you’re already invested in HashiCorp products, Nomad extends that investment to the edge. Native integration with Vault for secrets, Consul for comprehensive service discovery, and Sentinel for policy enforcement means workload identities and governance flow through without additional complexity or integration work.
What does OpenShift bring to the Nomad control plane?
As with any Kubernetes-native workload, the practical value of running Nomad servers on OpenShift is in what you don’t have to build.
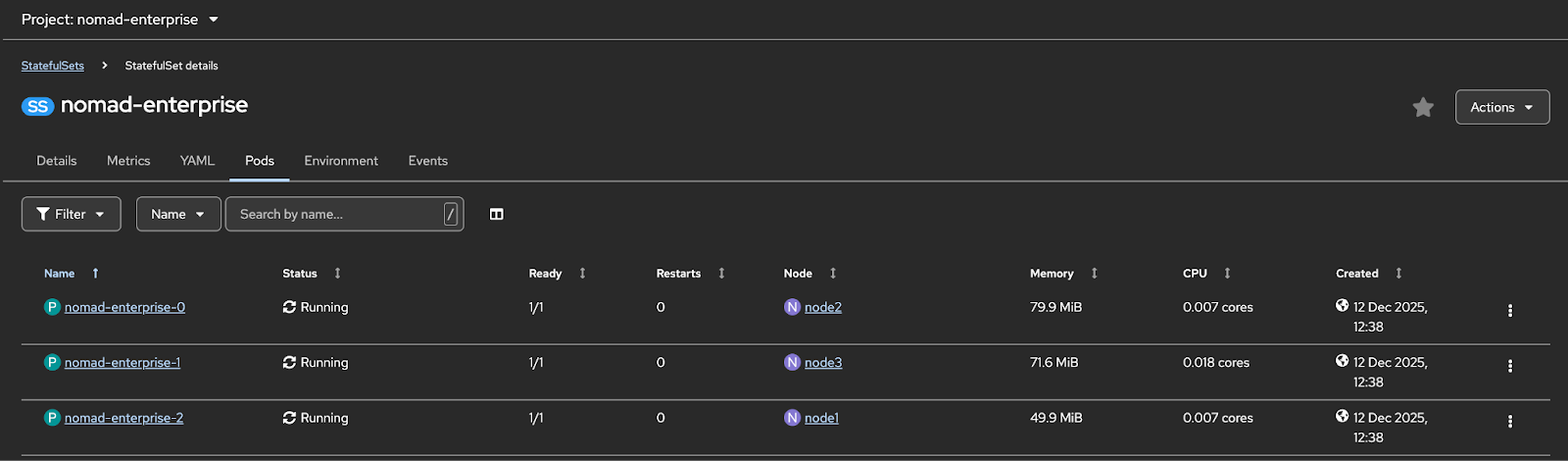
The StatefulSet abstraction aligns naturally with Nomad’s requirements in that each Nomad server gets a stable network identity and persistent storage that survives pod rescheduling. Pod anti-affinity rules ensure that servers are distributed across failure domains, and if a node fails, Kubernetes handles rescheduling automatically. Combined with Nomad’s Raft consensus, this provides control plane resilience without requiring custom automation or extensive bespoke documentation for common failure scenarios.
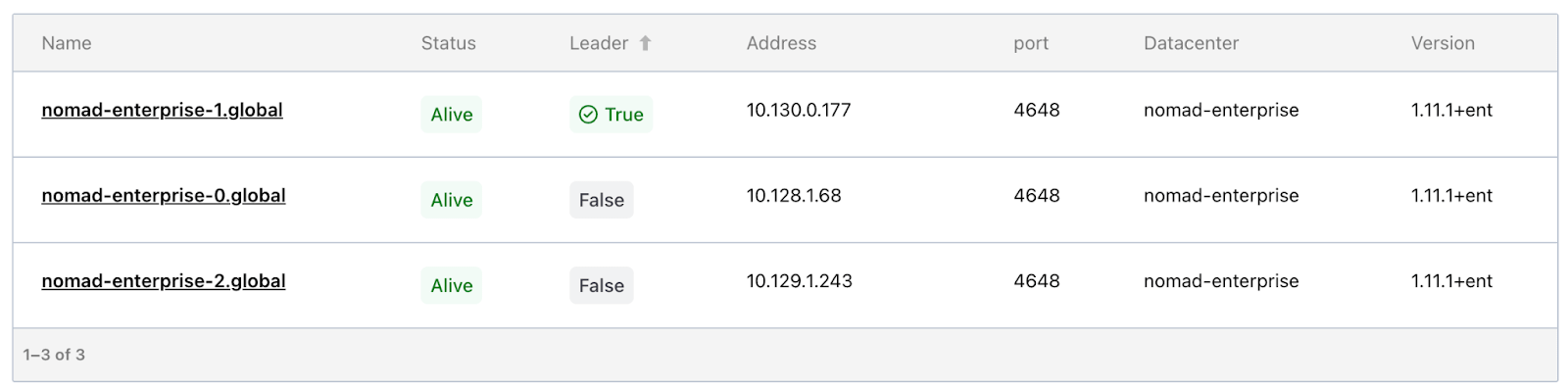
Security controls then become inherited from the platform rather than a bespoke configuration. OpenShift’s Security Context Constraints limit what the Nomad server pods can do, RBAC governs who can manage the deployment, network policies restrict traffic flow, and platform logging capabilities capture operational and audit logs alike. These are not Nomad-specific investments - they’re capabilities your platform team is already using for everything else on the cluster, applied consistently to one more workload.
The same applies to observability. Prometheus scrapes Nomad’s metrics endpoint alongside every other workload, alerts flow through Alertmanager, and logs land in your existing cluster logging stack. There is no separate monitoring infrastructure to maintain for the Nomad control plane - it’s just another application from an operations perspective.
The operator ecosystem also extends what Nomad can do without additional integration work. The Vault Secrets Operator (VSO) can synchronize PKI certificates and other operationally sensitive data from HashiCorp Vault to Kubernetes Secrets, which the StatefulSet then mounts and consumes. Certificate rotation becomes a Vault operation rather than a configuration management exercise - Vault dynamically renews the certificate, and the VSO propagates that change. OpenShift GitOps can also manage the deployment of the Nomad Kubernetes resources declaratively, maintaining management parity with other OpenShift cluster workloads.
Ultimately, you’re composing existing products provided by both the platform and the Red Hat and HashiCorp ecosystems, rather than building bespoke integrations for each capability that Nomad requires for a production-grade deployment.
The impact on the HashiCorp Validated Design
The HashiCorp Validated Design (HVD) for Nomad Enterprise provides comprehensive guidance for production deployments, covering everything from server sizing to availability zone distribution to backup strategies. Much of that guidance assumes a VM-based deployment model where infrastructure recovery is measured in minutes rather than seconds. When the Nomad servers run on Kubernetes, some of that guidance becomes unnecessary as the platform already solves the underlying problem.
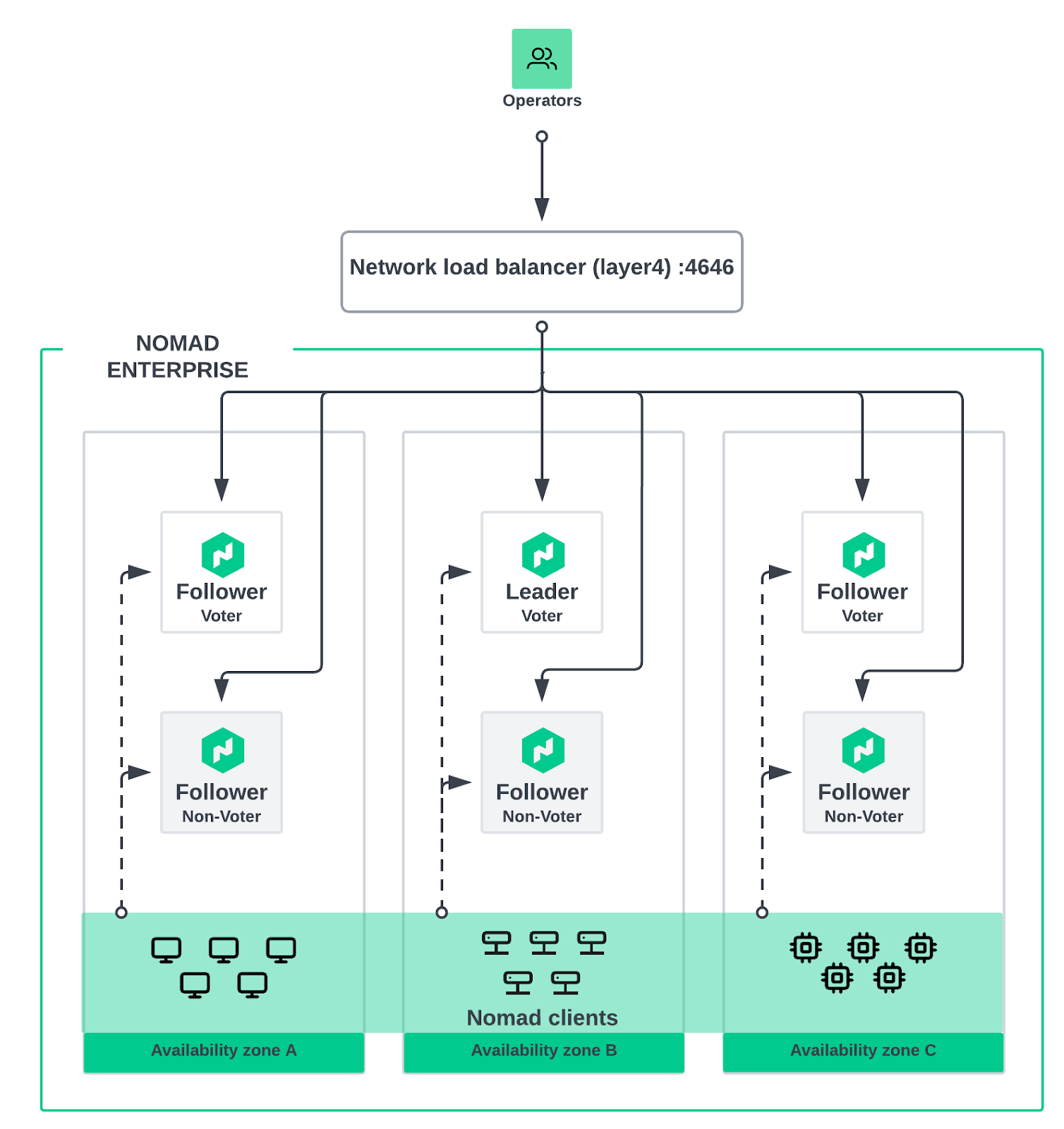
The clearest example is in the configuration of redundancy zones. The HVD recommends six servers arranged as voter/non-voter pairs across three availability zones. If a voter fails, Autopilot promotes the non-voter in the same zone, providing a “hot standby” that can take over without waiting for infrastructure recovery. This pattern exists because replacing a failed VM takes time - provisioning, bootstrapping, rejoining the cluster - and you don’t want to be running with a degraded quorum while that happens.
Kubernetes changes this operating model. Pod rescheduling typically completes in seconds. The StatefulSet preserves identity, so nomad-0 rejoins as nomad-0 with its existing persistent volume. Raft handles the temporary quorum disruption during rescheduling. A three-replica StatefulSet with topology spread constraints provides equivalent availability without the operational overhead of managing voter/non-voter topology. You’re not building redundancy into the application layer because the platform layer already provides it.
The zone distribution itself is also simplified. Even without voter/non-voter pairs, you want servers spread across failure domains. The HVD describes the placement of servers and the configuration of their redundancy_zone parameter, but on Kubernetes, topology spread constraints handle this declaratively. You specify the desired distribution, and the scheduler enforces it. If a node fails, the replacement pod lands in an appropriate zone automatically.
This is not a criticism of the HVD. The guidance it provides is absolutely valid for VM-based deployments where these are problems that genuinely need solving. However, recognizing which recommendations become platform concerns rather than application concerns is part of deploying the Nomad servers effectively on Kubernetes. You’re inheriting platform-provided solutions to these problems rather than reimplementing them.
Considerations
This architecture makes sense in specific circumstances, but it’s worth being explicit about when it doesn’t. The first consideration is whether you have OpenShift - or even Kubernetes - in the first place. The marginal cost argument, that Nomad servers are just another StatefulSet, only holds if the platform already exists. Standing up an OpenShift cluster specifically to host Nomad servers would be difficult to justify; you would be better served by the VM-based deployment model the HVD already describes in detail.
Similarly, the value here is for infrastructure that your chosen Kubernetes distribution genuinely can’t reach. Enterprise organizations value standardisation - they’re an OpenShift shop, or an EKS shop, or an AKS shop - and that standardisation is deliberate. If your “edge” consists of rack-mounted servers in retail locations or regional datacenters that could comfortably run your standard distribution, extending that distribution may well be the simpler answer. The case for Nomad is strongest when you have devices where your standard Kubernetes distribution is not an option: single-board computers, legacy systems and services, hardware with constrained resources, problematic network topologies that impact how Kubernetes manages nodes and schedules workloads, or environments and workloads for which container runtimes just aren’t viable. If that’s not the situation you find yourself in, you might be adding operational complexity without the compelling event to justify it.
Team capability matters as well. Running Nomad alongside OpenShift means your platform team needs to understand both systems - not just deployment, but day-two operations, upgrades, and troubleshooting. If no one on the team has Nomad experience, there is a learning curve to account for. The operational model is much simpler than running Nomad on VMs, but it’s not zero.
Finally, while Kubernetes solves many of the high-availability problems that the HVD addresses, both storage availability and performance remain genuine considerations. Nomad servers are sensitive to storage latency, particularly under scheduling load. If your OpenShift storage backend can’t deliver consistent IOPS, you will see leader election instability or slow job scheduling. This is a solvable problem, which OpenShift Data Foundation, with appropriately configured storage classes, handles well, but it is worth validating early rather than discovering in production.
Storage for Nomad clients presents a different challenge. In heterogeneous and distributed environments, you can’t rely on centralized storage backends or Container Storage Interface (CSI) plugins that assume reliable connectivity to a provisioner. For most edge deployments, local storage on the device itself is the pragmatic answer - Nomad’s host volume configuration exposes local paths to allocations without external dependencies. This is not a limitation of the architecture described here; it is an inherent characteristic of distributed edge infrastructure that you will need to address regardless of how the control plane is deployed.
Being aware of these challenges up front will help you create an approach that best fits your workloads and the infrastructure domain in which you need to run them.
Next steps
For organizations already running OpenShift and facing orchestration challenges on infrastructure that Kubernetes can’t reach, this pattern opens up the possibility of bringing those devices into a managed fleet without the traditional control plane investment. Edge workloads that would otherwise require manual deployment or bespoke tooling can participate in the same operational model as everything else - declarative job definitions, centralized visibility, and consistent lifecycle management.
A reference Helm chart implementing the architecture described here is available in this GitHub repository. It covers the StatefulSet, service configuration, observability integration, and snapshot agent - treat it as a starting point to adapt rather than a supported artifact. In addition, the HashiCorp Developer site offers a hands-on tutorial for managing edge workloads, lessons that are applicable irrespective of the deployment model chosen.
This approach makes use of several Nomad Enterprise capabilities: audit logging for security and compliance visibility, the snapshot agent for automated backups to a supported storage provider, and Autopilot for cluster health management during rolling updates and pod rescheduling. If you want to try this out for yourself, request your Nomad Enterprise trial today!

Clever. You really nailed the K8s-at-the-edge problem. It’s refreshing to see a focus on lightweight solutions like Nomad for things like AI inference on truly resource-constrained devices – they’d practially scream if you so much as whispered ‘kubelet’.